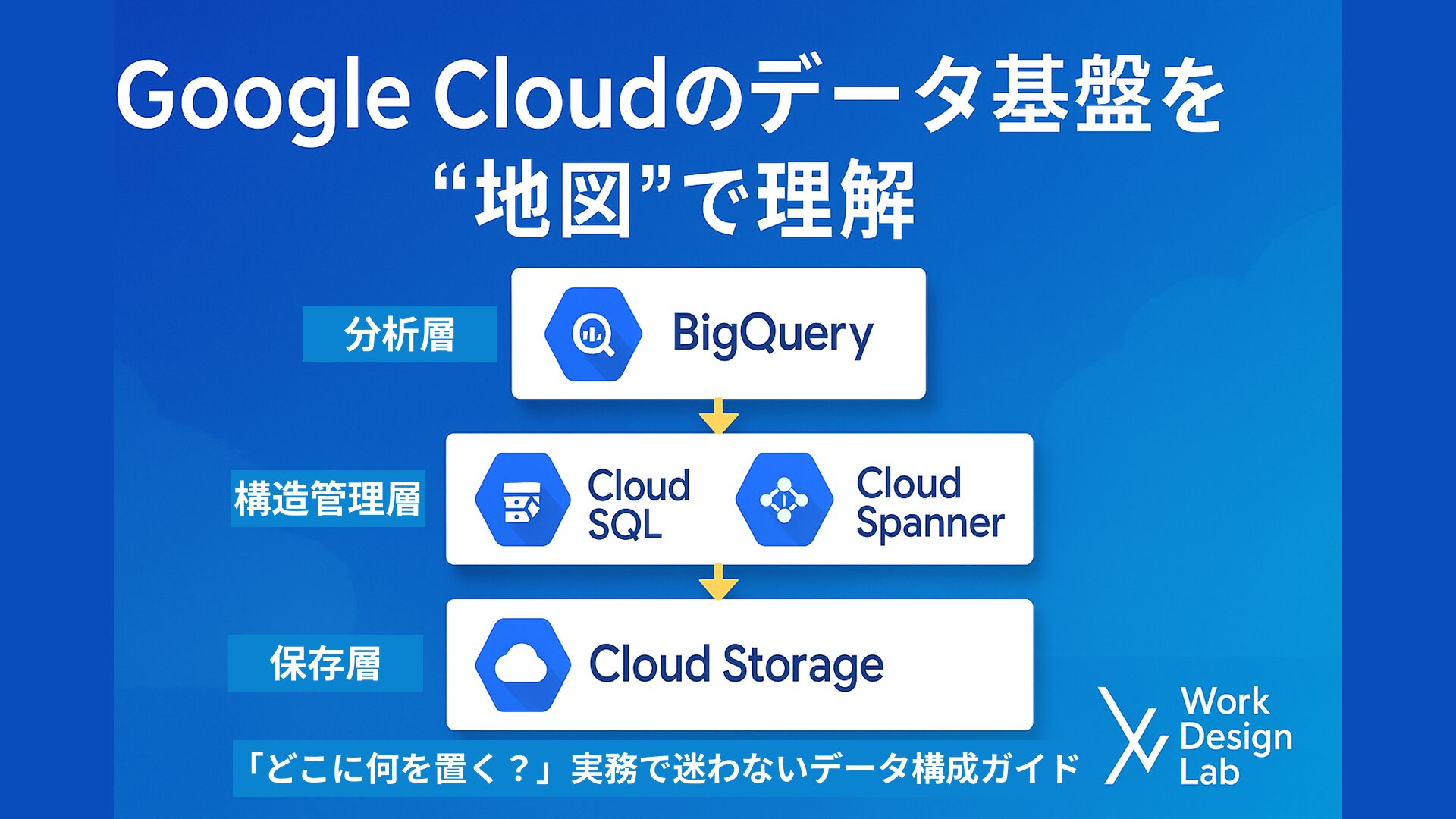
1. まず大分類:Google Cloudのデータ系サービスの地図
Google Cloudのデータサービスは、大きく3階層に分かれます:
| 層 | 目的 | 主なサービス |
|---|---|---|
| ① ストレージ層(保存する) | データをとにかく安全に置く | Cloud Storage |
| ② データベース層(構造的に管理する) | アプリ・業務で扱うデータ | Cloud SQL / Cloud Spanner / Firestore / Bigtable |
| ③ 分析層(大量データを分析する) | 集計・可視化・AI分析 | BigQuery |
2. 各サービスの性格をざっくりイメージ
🔹 Cloud Storage(クラウドストレージ)
-
データの“倉庫”。
-
画像・動画・CSV・バックアップなど、ファイルそのものを保管。
-
フォルダ構造ではなく「オブジェクトストレージ」=クラウド版ハードディスク。
-
例:
gs://my-bucket/data/file.csv
👉 非構造化データ(構造を持たないデータ)を扱う。
🔹 Cloud SQL
-
クラウド版のMySQL / PostgreSQL / SQL Server。
-
普通のアプリ(ECサイト、顧客管理、社内システム)で使われる“リレーショナルデータベース”。
-
トランザクション(ACID)対応。
-
単一リージョン中心・中規模向け。
👉 従来の業務DBの「クラウド移行先」。
🔹 Cloud Spanner
-
グローバル分散リレーショナルDB。
-
Cloud SQLのようにSQLが使えるが、世界中にまたがってスケール可能。
-
大規模システム・SaaS・金融などに最適。
-
強みは「スケールアウト」と「トランザクション整合性の両立」。
👉 Cloud SQLの“上位互換ではなく、スケーラブル版RDB”。
🔹 Firestore(NoSQL)
-
JSONのような階層構造を持つドキュメント型DB。
-
柔軟だが、トランザクションや複雑JOINには弱い。
-
モバイル・Webアプリのリアルタイム更新に最適。
👉 アプリ・チャット・SNS系に強い。
🔹 Bigtable(NoSQL)
-
時系列・IoT・ログ・分析向けの超大規模DB。
-
構造はシンプル(テーブル+キー+カラム)。
-
検索・分析に特化しており、トランザクションは弱い。
👉 分析やAIモデルのデータソースとして使う。
🔹 BigQuery
-
データウェアハウス(DWH)。
-
何十億行でもSQLで一瞬で分析できる。
-
Cloud SQLやStorageなど“他のサービスからデータを集めて解析する場所”。
-
ストレージ+分散クエリエンジンがセットになっている。
👉 分析用RDB。OLAP向け。
(Cloud SQLやSpannerが扱うのはOLTP=業務処理用)
3. RDB(リレーショナルデータベース)の軸で整理
| 比較軸 | Cloud SQL | Cloud Spanner | BigQuery |
|---|---|---|---|
| タイプ | RDB(OLTP) | 分散RDB(OLTP) | 分析DB(OLAP) |
| 主用途 | トランザクション処理(業務) | グローバル・大規模業務処理 | データ分析・BI |
| 構造 | テーブル+行+列(SQL) | 同左(スケールアウト対応) | 同左(ただし分析特化) |
| トランザクション | 強い | 非常に強い(分散対応) | 弱い(分析のみ) |
| スケール | 垂直(性能アップ) | 水平(ノード追加) | 水平(自動分散) |
| 主な利用例 | 顧客DB、会計、在庫管理 | 金融・SaaS共通DB | BIダッシュボード、AI分析 |
👉 「業務データ」はCloud SQLやSpannerで、“分析”はBigQueryで行う。
つまり、「保存と分析で役割を分ける」ことが重要。
4. よくある混乱ポイント(間違えやすい)
| 誤解 | 正しい理解 |
|---|---|
| 「BigQueryもSQLって名前だからRDBだよね?」 | SQL文は使うが、目的が違う(分析用)。トランザクション制御はない。 |
| 「Cloud Storageに入れたCSVをそのまま分析できない?」 | BigQueryから外部テーブルとして参照可能。ただし読み込みコストが高い。 |
| 「Cloud SQLを使えばすべて解決?」 | スケールが限定的。大規模化したらSpannerやBigQueryに分担させる必要あり。 |
| 「FirestoreとCloud SQLは同じ?」 | 違う。FirestoreはNoSQL。構造が柔軟でJOIN不可。Cloud SQLはRDBで厳密構造。 |
5. どこに何を置く? — 実務的な指針
| データの種類 | 保存場所 | 理由 |
|---|---|---|
| 画像・動画・ログファイル | Cloud Storage | 非構造化データ(ファイル単位) |
| 顧客情報・会計・販売など | Cloud SQL / Spanner | リレーショナルデータ+トランザクション |
| IoT・センサーデータ・ログ | Bigtable / Pub/Sub + Dataflow | 時系列+高速書き込み |
| それらを集約・分析 | BigQuery | 大規模集計・BI・AI連携 |
このように、役割分担が肝です。
現代のデータ基盤は「1つのDBで全部」ではなく、
“Data Lake + Data Warehouse + Operational DB”の連携で成り立っています。
6. 全体像を図でまとめる(頭に残る地図)
┌──────────────────────────────┐
│ アプリ・業務処理層(OLTP) │
│ ├ Cloud SQL → 中小規模RDB │
│ ├ Cloud Spanner → 大規模分散RDB │
│ └ Firestore → 柔軟なNoSQL │
└──────────────────────────────┘
↓(データ蓄積)
┌──────────────────────────────┐
│ データレイク層(Raw Data) │
│ Cloud Storage / Bigtable │
└──────────────────────────────┘
↓(集計・分析)
┌──────────────────────────────┐
│ データ分析層(OLAP) │
│ BigQuery │
└──────────────────────────────┘
7. まとめ:リレーショナルDBを中心に見るなら
| 項目 | Cloud SQL | Cloud Spanner | BigQuery |
|---|---|---|---|
| 性質 | 伝統的RDB(MySQL/PostgreSQL) | 分散RDB(Google流RDB) | 分析用SQLエンジン |
| 主用途 | アプリ・業務処理 | グローバルな大規模業務 | データ分析・BI |
| ACID保証 | あり | あり(分散でも保証) | なし(分析中心) |
| 運用 | マネージド | マネージド | フルマネージド |
| 規模感 | 小〜中 | 大規模 | 超大規模データ分析 |
最後に一文で言うと
Cloud SQL は「日々の業務の正確さ」、
BigQuery は「全体の洞察」、
Cloud Storage は「すべての土台」。
そして Cloud Spanner は「世界規模でも整合性を保つための究極のRDB」。

コメント